Projects
InvestNotes
Built a multi-market portfolio tracker (NSE, NASDAQ, NYSE) with Next.js 14, Supabase, and TradingView charts, supporting real-time P&L tracking, cash allocation, and transaction management — deployed on Vercel.
- Architected serverless business logic using Supabase Edge Functions and cron jobs for transaction processing, dynamic price caching via Yahoo Finance, and automated daily portfolio refresh.

MachineHack Hackathons
The repository contains notebooks of various MachineHack Hackathons covering multiple domains of Machine Learning and Deep Learning Worlds:
- Regression Problems
- Classification Problems
- Time Series Problems
- Range Prediction Problems

BOTAnshul
- Redesigned the future of employer-employee interaction in form of a personalized chatbot resume using python's open-source library Rasa.
- Deployed the mini version of me on a personal website using Heroku docker services, making conversations available 24×7 and accessible from any part of the world.
automeans
- Python Library for automating the scikit-learn K-Means Clustering Algorithm by optimising the selection of number of clusters.

Handy Cricket
- The game was made using powers of Open-CV and Keras library to identify hand signals denoting runs scored.
- The game would be played between you and the computer.
- Score more than the computer to win the Game.
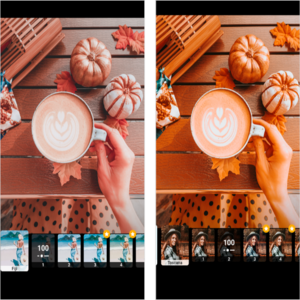
PhotoEditor using OpenCV
- Apply Instagram-like filters or adjust/edit your Images using commands of OpenCV Python Library.
- Created a UI using Gradio Library to share the project.

Speaker Diarization
- Investigated state-of-art methods and speech processing techniques used in preexisting Speaker Diarization systems to identify the number of speakers and segmenting their respective speech time in conversational audio signals.
- Devised a novel framework and developed a model on features extracted from ‘The ICSI Meeting’ and ‘The AMI’ corpus using pyAudioAnalysis for segmentation and Hierarchical clustering for recognizing speakers.
Slytherin Game using Genetic Algorithm
- Developed a Genetic Algorithm for the old Snake Game using pygame library, resulting in a better score for computers than humans after mutating through a series of generations.
AMBeats: Android Music Player with Recommender System
The project involves developing an android app that displays all the songs stored in the local storage that can be played using a minimalistic user interface. The interface allows users to like the songs they hear and those songs are then saved onto an online database. These liked songs were then compared with other users who liked similar songs to provide new recommendations using Machine Learning algorithm.
View Project
Playback Attack Detection for Speaker Verification Systems
The project was a research-oriented work that involved extracting cepstral features from audio obtained from the ASVSpoof 2017 benchmark dataset, which were then analyzed to find out which features better affect the decision of whether the spoken speech is genuine or spoof.
View Project
Next-Word Prediction
The project involves developing a N-gram probabilistic model that predicts the next possible words based on the entered word or a sentence by the user. The prediction made by a pre-trained model trained on the text of multiple storybooks.
View Project
Named Entity Recognizer Guide
The project utilizes a combination of python and natural language processing to create a custom model that helps machine classify text based on person, location, money, time, date and much more. We show the use of Bidirectional LSTM and BERT Models to overcome the problem. The project can be launched as demo version using Gradio.
View Project